深度学习基础概念 -- 规范化Normalization
Normalization 技术是深度学习中一个非常重要的概念,中文常翻译成“规范化”,从 2015 年 Google 提出 Batch Normalization(BN)后,由于实际效果非常好,BN 很快就成了深度学习领域的标配工具,后续的几年,针对不同场景的 Normalization 技术也在不断地被提出.
这篇文章主要是想整理 Normalization 相关知识点,后续会时不时更新,文章主体涉及以下两个层面
- 如何理解 Batch Normalization
- 常用 Normalization 技术对比
如何理解 Batch Normalization
Batch Normalization 定义
Batch Normalization 作为 Normalization 方法中最有代表的技术,其基本思路就是通过一定的规范化方法,将神经网络内部每一层的输入变换至均值为 0 方差为 1 的标准正态分布。至于为什么要这么做,首先需要解释一个概念:
Internal Covariate Shift(ICS):通过实验可以观察到,神经网络内部每一层输入数据都有相应的分布,在训练过程中会受到网络参数初始化和输入数据随机性的影响。这种网络内部输入数据分布被影响的现象就被称作 ICS。
BN 最初被提出来就是为了解决 ICS 现象。一个很直观的认知就是,网络在训练阶段,随着前一层参数的变化,其输出分布也会随之变化,所以后层也同样需要不断地调整参数以适应新的分布。随着网络深度加深,整体分布的偏移(比如往非线性函数的饱和区间靠近)会导致模型收敛变慢。而 BN 可以理解成,每个隐层神经元将映射到非线性函数(比如 Sigmoid)靠近饱和区间的输入分布,强行拉回到相对偏线性的区域,也就是人为增大梯度,从而避免梯度消失问题。
在思想上 BN 借鉴了数据预处理中的白化(whitening)的概念,希望让数据做到独立同分布(Independent and identically distributed,iid),因而 BN 可以认为是对白化(whitening)操作一种改进,比如为了降低计算量,仅针对 mini batch 而非全部样本的单个 feature 进行操作,同时通过仿射变换在一定程度上减缓白化操作可能导致的网络表达能力丢失的问题。
Batch Normalization 操作流程
BN 操作通常会涉及以下几部分
-
BN 规范化的计算步骤
整个 BN 的变换简单来说就是如下公式所示
可以分为三步:
- 针对 mini-batch,计算均值 以及方差
- 标准化
- 缩放 以及偏移
问:前面两步比较好理解,为什么还需要第三步呢?好不容易标准化了,难道还得再变回去?
答:之前提到,BN 的基本思想是把输入分布由非线性函数的饱和区调整到偏线性区域,这在一定程度上会降低整个网络架构的表达能力,所以需要再次人为做些调整,稍微偏离线性区域,具体参数由模型自行学习。
-
BN 变换后的反向传播计算
同样可以由链式法则求得,具体推导略。
-
BN 规范化后的单个新样本推理(Inference)
问:由于 BN 算法本身的特殊性(针对 mini-batch,计算均值 以及方差 ),当面对单个新样本的推理时,均值与方差从何而来呢?
答:在训练过程中,每一个 mini-batch,其实都是保存了相应的均值与方差的,所以从数学层面,可以推算出来整体训练样本的均值与方差,以供推理时使用。
Batch Normalization 优缺点
-
✔️ 更快地使模型收敛;
-
✔️ 可以使用更高的学习率而不会导致梯度消失或爆炸;
在 BN 之前,普遍认为,使用 Sigmoid 激活函数几乎无法有效训练非常深的网络模型。
-
✔️ 降低模型参数初始化的难度;
-
✔️ 一定程度上提供了正则化的效果;
由于 BN 可以被看成是向网络中加入部分噪声,所以 BN 起到了类似 Dropout 降低过拟合的作用,从而进一步提高了网络泛化特性。
-
❌ BN 强烈依赖于 mini-batch,所以 batch size 较小的时候,效果比较差;
-
❌ BN 训练阶段与推理阶段计算方法不一样;
-
❌ BN 在 RNN 中效果比较差;
由于 RNN 是一个动态网络架构,Sequence 是变长的,所以 BN 并不能有效地计算均值与方差。
-
❌ 在很深的网络(>50 层),BN 可能会造成梯度爆炸;
这个结论来自 2019 年微软的 一篇文献,说实话,原文 95 页公式,硬是没找到一个直观点的解释,明哥我也没看明白,所以这里只能大概贴个结论,期待有大神看到后能够指点一二。
原文大概意思是说,根据激活函数的不同,每经过一层网络,梯度就会被放大倍( ),比如,对 ReLU 函数而言, 当 batch size 趋近于无穷大时, 会降低到,对于 50 层以上的网络,这个数值将会大到爆炸,而且不管是什么样的非线性激活函数,都存在这个问题,残差网络中的跳跃连接(Skip connections)目前算是一种应对方案。
这个理论感觉跟我们日常所了解的 BN 功能有点相悖,但个人认为也不能完全排除这种可能性,之前文献讨论大多的是单个 BN 变换引起的变化,而这篇文章更多地则是强调多层 BN 级联带来的效果,或许这也可能是很深的网络无法训练好的原因之一吧。
Batch Normalization 为何有效
由于 BN 的效果确实比较好,大家就想了解背后的机理。目前业界大概提出了以下几种假设:
-
观点 1:BN 是解决了 Internal Covariate Shift(ICS)问题; 该观点已基本被否定。2018 年,MIT 的学者通过在 BN 变换后人为引入一些随机扰动,证明了 BN 的有效性与 ICS 无关。这个大概很多人都清楚了,不再赘述。
-
观点 2:BN 消除了隐层之间的耦合;
这个观点目前没发现有明确的文献支持,但相对而言比较符合认知。Ian Goodfellow 在讲解 BN 概念的时候,大致提到过,由于梯度在更新的时候,各个层之间通常以级联的方式互联,所以层与层之间存在一定的耦合,BN 的操作一定程度上修正了输入的分布,从而能降低前后层之间的耦合。
-
观点 3:BN 使目标函数曲面更加平滑;
BN 通过参数重整(reparametrize),在保持原先最优点几乎不变的情况下,可以让损失函数及其梯度满足更强的 Lipschitzness 条件(更小的 L-Lipschitz 以及-smooth 常数),从而让目标函数的空间曲面变得更加光滑,加快模型的收敛速度。
简单来说,就是在 BN 加持下,损失函数的空间曲面由类似山陵地带的形状变成了几近平原的样貌,而原先的那些优化点则依然保持不变。这套理论因为跟实验观察到的结果比较贴切,目前得到了广泛接受。
-
观点 4:权重空间的大小与方向的解耦;
该观点受到 Weight Normalization(WN,2016 年)启发,作者认为,BN 通过参数重整(reparametrize),实际等效于在训练过程中对权重(Weight)向量的长度(length)和方向(direction)进行解耦操作,这样有助于模型的快速收敛。
-
BN 具体的工作原理,目前说实话还没有定论。上述观点 2 比较好理解,但还缺少有力的证明,观点 3 和观点 4 主要是尝试从数学层面进行解读,由于具体推导过程研究不深,个人也不太敢妄加评论,暂且归纳在此。
Batch Normalization 注意事项
-
问:BN 模块是放在激活函数前还是之后?
答:原文献是将 BN 放置在激活函数前,但相关 实验 证明,放在激活函数之后效果更好。
目前大多数框架都采用了 BN 前置的策略。
-
问:BN 能直接用于(样本)输入的规范/标准化吗?
答:虽然 BN 最初并非用于输入层,但也可以这样来用,不过需要注意两点:
- BN 强烈依赖于 batch size,所以如果输入样本数量较少,必然会导致样本偏差的问题;
- 标准 BN 的实现通常包含了缩放与偏移系数 、,针对输入层不需要使用这两个参数;
当然,对于输入数据的预处理还是建议使用专门的模块,比如 sklearn's StandardScaler 等等,使用上也会方便些。
常用 Normalization 技术对比
针对 BN 的优势与不足,业界这几年又陆续推出了不少 Normalization 变体,单看 PapersWithCode 就有几十种之多。现将一些常见的 Normalization 技术做一些简单的归纳,通过横向类比,也可以大致窥探 Normalization 技术的一些共性特征。
考虑输入数据维度的不同
BN 从实现层面上来说,实际上是考虑 mini batch 个输入样本、单个神经元,在 feature map 维度统计均值方差,单就 CV 而言,假设输入是(N,C,H,W),那就相当于在针对 channel 来做变换。这种直觉下很容易想到能不能从其他维度去考虑,以下几种方法就是这种思路。
-
Layer Normalization(LN,2016 年)
LN 就是针对一个样本同一层 layer 上的所有 feature,而不是考虑 batch size 内所有样本的同一个 feature,直观来说就是,LN 针对(N,C,H,W)中的 batch N 维度来做变换。正因为如此,LN 不受 mini batch 分布的影响,可以适用于 RNN 或者 batch size 较小的模型。
-
Instance Normalization(IN,2017 年)
IN 最初是用于图像的风格迁移,其基本思想就是把每个(H,W)单独拿出来标准化处理以及仿射变换。这样操作的好处是可以保持每张图像的独立性,不受 channel 与 batch size 的影响。
-
Group Normalization(GN,2018 年)
GP 可以认为是 LN 与 IN 思想的一种结合,对 channel 进行分组,再对各组通道分别进行标准化处理以及仿射变换,从这个角度来看,LN 相当于 GP 设置了 1 个分组,IN 相当于 GP 设置了全部通道数量的分组。
综合来看,BN 考虑的是 Mini-Batch 中不同的训练样本经过同一个神经元,LN 考虑的是同一个训练样本经过同一隐层所有神经元,IN 则是只考虑单个通道,而 GroupNorm 则考虑了通道分组的思想。这几种方法的对比如下图所示:
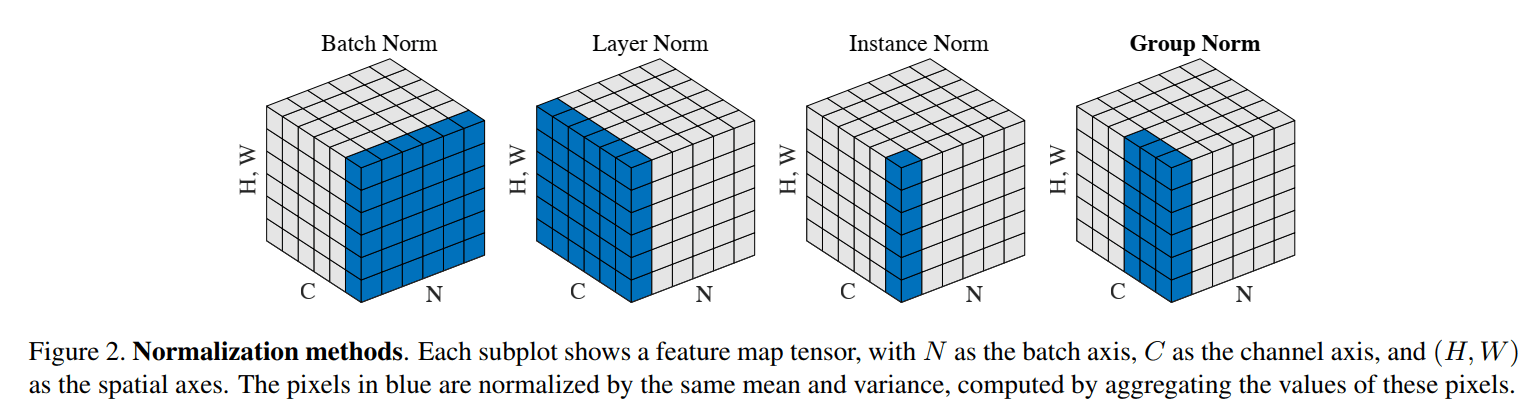
考虑归一化/标准化方法的不同
BN 的 Normalization 具体实现是将数据集调整到均值为 0,方差为 1,类似 Z-score,对应于 Sklearn 的 StandardScaler(),那么很容易想到其他归一化/标准化方法是否有效,比如 MinMaxScaler()、MaxAbsScaler()等等,以下几种方法就是类似思路,主要关注归一化/标准化方法。
-
Filter Response Normalization(FRN,2019 年)
FRN 其实是针对 IN 做了小幅改进,同样是在 (H, W) 维度上进行 Normalization,但 FRN 放弃了对均值 的使用,这样导致归一化的结果存在整体的偏移,为此作者还采用了改进版的激活函数 Thresholded Linear Unit (TLU)。
考虑仿射变换参数学习方法的不同
BN 的标准实现最后一步涉及到仿射变换(缩放 以及偏移 ),这两个参数的确定显然是可以进一步挖掘的,以下方法就是基于这种思路。
-
Adaptive Instance Normalization (AdaIN,2017)
AdaIN 的提出是为了确定风格迁移中原始图像的仿射变换参数。
作者没有采用单独的一个 style 特征提取模块,而是直接使用风格图像中计算出来的缩放 以及偏移 参数。
考虑参数空间的优化
上述分类基本都是围绕 BN 标准实现的三大步骤来进一步发散。除此以外,还出现了一个新的思路。如果说前三类 Normalization 变体主要着眼于输入数据层面,那么以下这种大概就可以归结于网络参数层面。
-
Weight Normalization(WN,2016 年)
WN 的基本思想是将参数空间拆分为长度(length)和方向(direction)分别进行训练,由于不需要批处理均值与方差,WN 在进行传播计算时开销会更小,因此,理论上能达到更快的收敛速度。
这里需要说明的是,WN 和 BN 都采用了参数重整(reparametrize)的方法,虽然从表面上来看,BN 针对的是 feature map 的 Normalization,而 WN 针对的是权重(weight),但对 WN 进行适当的数学推导就能发现,两种方法本质上都是针对 feature map 的标准化,只不过 BN 是除以输入数据本身的方差进行缩放,而 WN 则是针对权重(weight)的 范数缩放,从这个意义上来说,WN 可以认为执行的是一种特殊的标准化操作。也正是因此,WN 相对 BN 而言,会对模型的初始化参数会更加敏感。
总结
Normalization 可以说是一种非常实用的技术,本文对一些常见的概念做了总结与归纳。目前整体来看,真正涉及到 Normalization 核心的文章并不多,这也从侧面反映出 Normalization 背后的逻辑可能确实难以解释。尽管如此,这并不妨碍我们去了解 Normalization 所具有的一些优越的性质,比如单从实验来看,Normalization 的效果与 Dropout、Regularization 等殊途同归,此外,在文献 Layer Normalization(LN,2016 年)中,作者也提到了 Normalization 方法的权重与数据变换不变性(Invariance under weights and data transformations)性质,这一点也让人印象深刻。
Reference
- Batch normalization in 3 levels of understanding | by Johann Huber | Towards Data Science
- Why Batch Norm Causes Exploding Gradients | Kyle Luther
- Understanding the backward pass through Batch Normalization Layer (kratzert.github.io)
- Normalization Techniques in Deep Neural Networks | by Aakash Bindal | Techspace | Medium
- [R] How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift) : MachineLearning (reddit.com)
- [R] Towards a Theoretical Understanding of Batch Normalization : MachineLearning (reddit.com)