近期 OpenMMLab 开源了一个新的库 MMEngine ,根据官方描述,新版 MMCV 保留了部分之前的算子(operators),并新增了一些变换(transforms)功能,其余与训练相关的大部分功能(比如 runner、fileio 等)均已迁移至 MMEngine,新版训练测试脚本,功能更为强大,在接口、封装与调用逻辑等方面也做了大幅优化。
之前也断断续续浏览过 MMCV 项目的一些代码,但总感觉理解还不太到位,最近正好花了点时间学习了一下新版的 MMEngine,本文大致记录下心得体会。
考虑到新版本迭代还比较频繁,文中涉及到库与相关版本号如下(均可通过MIM直接安装):
MMCV:v2.0.0rc2 ;
MMEngine:v0.3.2 ;
MMDetection:v3.0.0.rc3 ;
以 MMDetection 中训练脚本为例,相关文件位于 mmdet/tools/train.py,忽略配置加载与模块注册之类的功能,调用 Runner 部分的代码如下
1 2 3 4 5 6 7 8 9 10 11 if 'runner_type' not in cfg:else :
测试部分 tools/test.py 主要差异就是调用 test() 方法,综合来看, 与 Runner 相关最重要的就是以下几行命令
1 2 3 runner = Runner.from_cfg(cfg)
接下来分步骤具体看下整个 Runner 调用流程。
1、整体流程构建
Runner 初始化
跟进 from_cfg(cfg) 方法,可以看出,实际是调用了类方法完成 Runner 的初始化,此处有必要贴一下具体代码,方便对配置文件 cfg 建立一个全局的认知
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @classmethod def from_cfg (cls, cfg: ConfigType ) -> 'Runner' :"""Build a runner from config. Args: cfg (ConfigType): A config used for building runner. Keys of ``cfg`` can see :meth:`__init__`. Returns: Runner: A runner build from ``cfg``. """ 'model' ],'work_dir' ],'train_dataloader' ),'val_dataloader' ),'test_dataloader' ),'train_cfg' ),'val_cfg' ),'test_cfg' ),'auto_scale_lr' ),'optim_wrapper' ),'param_scheduler' ),'val_evaluator' ),'test_evaluator' ),'default_hooks' ),'custom_hooks' ),'data_preprocessor' ),'load_from' ),'resume' , False ),'launcher' , 'none' ),'env_cfg' ), 'log_processor' ),'log_level' , 'INFO' ),'visualizer' ),'default_scope' , 'mmengine' ),'randomness' , dict (seed=None )),'experiment_name' ),return runner
从上述代码可以很清楚地看出一个完整的 cfg 可配置的选项具体包括哪些,如 model、train_dataloader、optim_wrapper 等。
接下来,进入 Runner 初始化部分,主要的操作有(已省略相关细节,下同)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Runner :def __init__ (... )self .setup_env(env_cfg)self .set_randomness(**randomness)self .default_scope = DefaultScope.get_instance(self ._experiment_name, scope_name=default_scope)self .log_processor = self .build_log_processor(log_processor)self .logger = self .build_logger(log_level=log_level)self ._log_env(env_cfg)self .message_hub = self .build_message_hub()self .visualizer = self .build_visualizer(visualizer)self .model = self .build_model(model)self .model = self .wrap_model(self .cfg.get('model_wrapper_cfg' ), self .model) self .register_hooks(default_hooks, custom_hooks)self .dump_config()
初始化相关代码主要试下以下功能:
基础环境配置:setup_env,设置随机种子 set_randomness,获取 default_scope (如 mmdet、mmcls 等);
实例化 log_processor、logger、message_hub、visualizer、model 等模块;
注册各类钩子 hooks (默认自带的 default_hooks 以及用户自定义的 custom_hooks );
模块延迟初始化 Lazy Initialization(此处未展示相关代码),如不同的 dataloader,仅当对应流程真正启动时,才需要完整实例化;
训练/验证/测试流程
这里直接贴出相关流程关键代码:
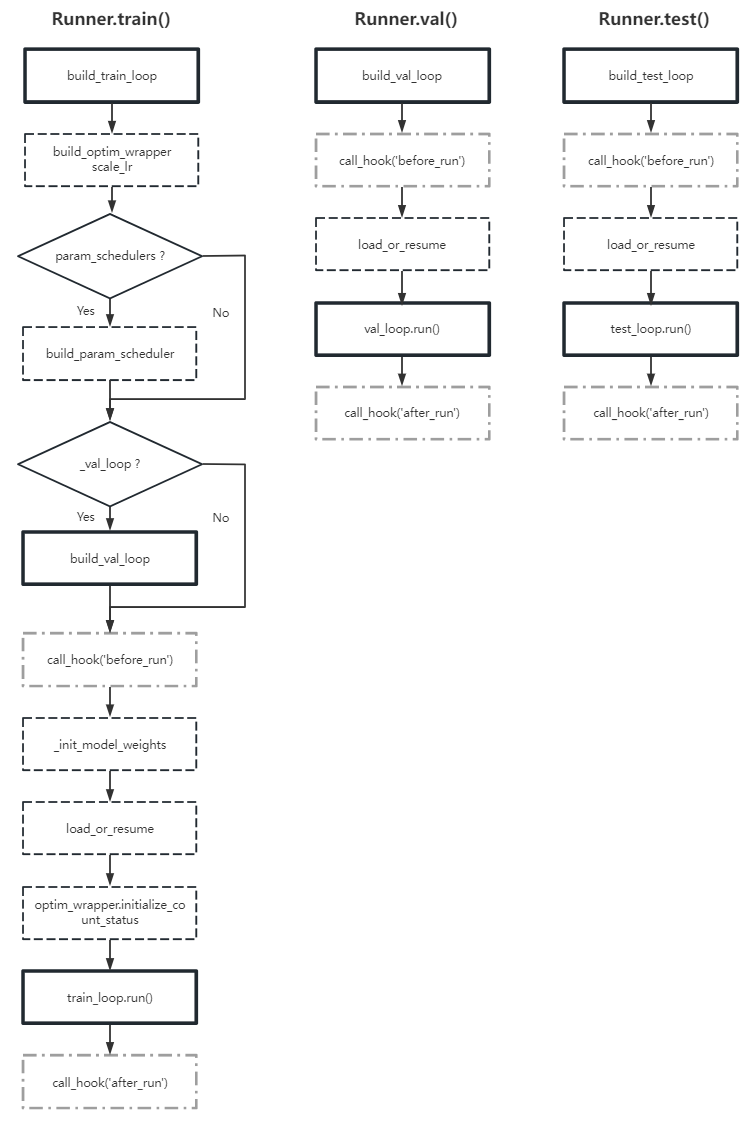
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def train (self ) -> nn.Module:self ._train_loop = self .build_train_loop(self ._train_loop)self .optim_wrapper = self .build_optim_wrapper(self .optim_wrapper)self .scale_lr(self .optim_wrapper, self .auto_scale_lr)if self .param_schedulers is not None :self .param_schedulers = self .build_param_scheduler(self .param_schedulers)if self ._val_loop is not None :self ._val_loop = self .build_val_loop(self ._val_loop)self .call_hook('before_run' )self ._init_model_weights()self .load_or_resume()self .optim_wrapper.initialize_count_status(self .model, self ._train_loop.iter , self ._train_loop.max_iters)self .train_loop.run()self .call_hook('after_run' )return modeldef val (self ) -> dict :self ._val_loop = self .build_val_loop(self ._val_loop)self .call_hook('before_run' )self .load_or_resume()self .val_loop.run()self .call_hook('after_run' )return metricsdef test (self ) -> dict :self ._test_loop = self .build_test_loop(self ._test_loop)self .call_hook('before_run' )self .load_or_resume()self .test_loop.run()self .call_hook('after_run' )return metrics
根据上述代码绘制的流程图如下
2、训练/验证流程详解
对照上述流程图,这里重点讨论以下(粗方框)几部分:
train 流程构建: build_train_loop
val 流程构建: build_val_loop
train 流程调用: train_loop.run()
val 流程调用: val_loop.run()
Train 流程构建与调用
1 2 3 4 5 6 7 8 9 10 11 12 13 def build_train_loop (self, loop: Union [BaseLoop, Dict ] ) -> BaseLoop:if 'type' in loop_cfg:dict (runner=self , dataloader=self ._train_dataloader))else :'by_epoch' )if by_epoch:self , dataloader=self ._train_dataloader)else :self , dataloader=self ._train_dataloader)return loop
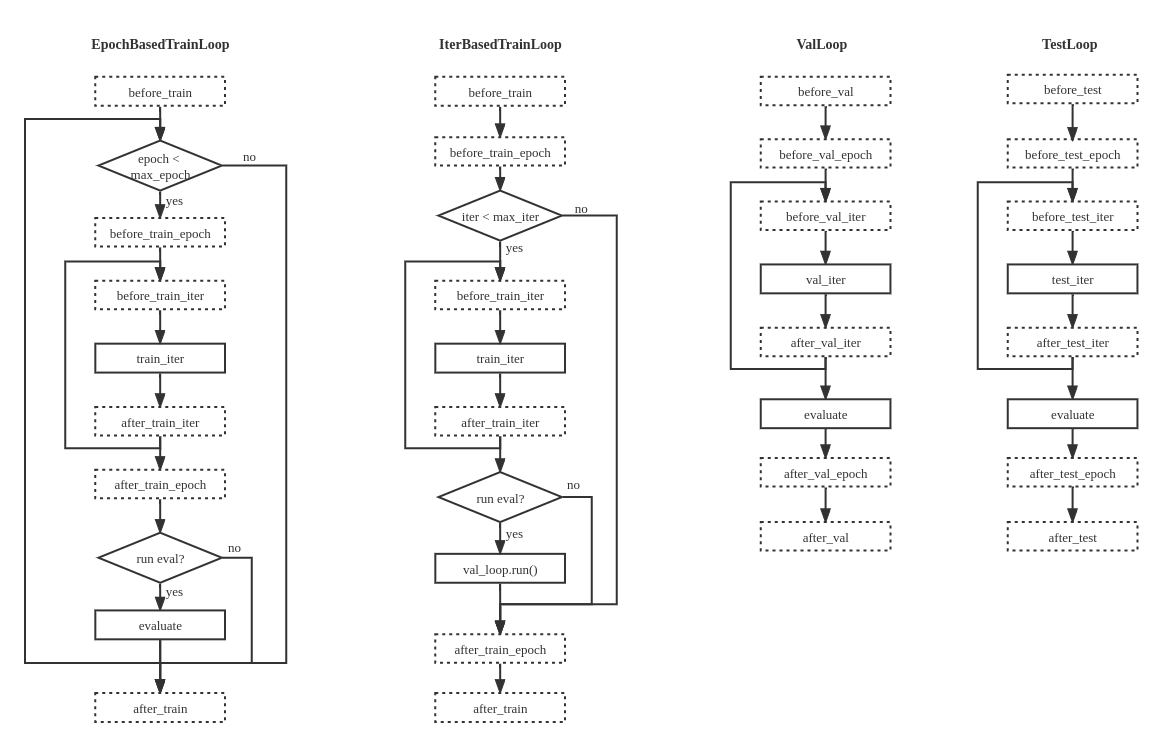
从上述代码片段可以看出,训练流程的构建主要涉及 EpochBasedTrainLoop 与 IterBasedTrainLoop 两种循环结构,分别对应按照 epoch 与 iteration 两种训练方式。
以 EpochBasedTrainLoop 类为例,其主要功能位于初始化 __init__ 与 run 方法部分,以下为整理后的核心代码(精简)片段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class EpochBasedTrainLoop (BaseLoop ):def __init__ (self, runner, dataloader, max_epochs, val_begin, val_interval, dynamic_intervals ):super ().__init__(runner, dataloader)self ._max_iters = self ._max_epochs * len (self .dataloader)if hasattr (self .dataloader.dataset, 'metainfo' ):self .runner.visualizer.dataset_meta = self .dataloader.dataset.metainfoself .dynamic_milestones, self .dynamic_intervals = calc_dynamic_intervals(self .val_interval, dynamic_intervals)def run (self ) -> torch.nn.Module:self .runner.call_hook('before_train' )while self ._epoch < self ._max_epochs:self .run_epoch()self ._decide_current_val_interval()if (self .runner.val_loop is not None and self ._epoch >= self .val_beginand self ._epoch % self .val_interval == 0 ):self .runner.val_loop.run()self .runner.call_hook('after_train' )return self .runner.model
从上述代码可以看出, EpochBasedTrainLoop 类实际上是继承了基类 BaseLoop,进一步跟进去,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class BaseLoop (metaclass=ABCMeta):def __init__ (self, runner, dataloader: Union [DataLoader, Dict ] ) -> None :self ._runner = runnerif isinstance (dataloader, dict ):'diff_rank_seed' , False )self .dataloader = runner.build_dataloader(dataloader, seed=runner.seed, diff_rank_seed=diff_rank_seed)else :self .dataloader = dataloader @property def runner (self ):return self ._runner @abstractmethod def run (self ) -> Any :"""Execute loop."""
此处,完成了 train_dataloader 的真正实例化操作,并且定义了抽象方法 run() 。
再次回到 EpochBasedTrainLoop 类的 run() 方法,现在总算是进入了真正的训练流程,为了方便理解,建议对照代码,同步参考官方提供的 循环控制器 相关流程图。
这里再进一步贴出 run() 方法中的训练相关的 run_epoch() 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def run_epoch (self ) -> None :self .runner.call_hook('before_train_epoch' )self .runner.model.train()for idx, data_batch in enumerate (self .dataloader):self .run_iter(idx, data_batch)self .runner.call_hook('after_train_epoch' )self ._epoch += 1 def run_iter (self, idx, data_batch: Sequence [dict ] ) -> None :self .runner.call_hook('before_train_iter' , batch_idx=idx, data_batch=data_batch)self .runner.model.train_step(data_batch, optim_wrapper=self .runner.optim_wrapper)self .runner.call_hook('after_train_iter' , batch_idx=idx, data_batch=data_batch, outputs=outputs)self ._iter += 1
至此,实际训练环节基本就清晰了,从 run_iter 中可以明显看出,最底层会调用 model.train_step 方法。
Val 流程构建与调用
当然,上述训练部分代码还会涉及到验证环节,可以进一步跟进到 runner.val_loop.run() 方法查看相关细节。
首先,看一下 ValLoop 部分的构建代码:
1 2 3 4 5 6 7 8 9 10 def build_val_loop (self, loop: Union [BaseLoop, Dict ] ) -> BaseLoop:if 'type' in loop_cfg:dict (runner=self , dataloader=self ._val_dataloader, evaluator=self ._val_evaluator))else :self , dataloader=self ._val_dataloader, evaluator=self ._val_evaluator)return loop
相较于训练构建流程,验证部分主要差异在于只有 ValLoop 一种循环,此外,还多了一个评估 evaluator 模块。
以下是其 run() 方法的相关实现,这里很明显的一个差异在于多了个 evaluator :初始话阶段会实现其实例化操作, run() 方法会调用 evaluator.evaluate() 来计算最终的 metrics,同时在 run_iter() 方法中会调用 evaluator.process() 实现每个 iteration 的数据处理工作。此外,容易看出, ValLoop 底层调用的是 model.val_step 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class ValLoop (BaseLoop ):def __init__ (self, runner, dataloader, evaluator, fp16 ):super ().__init__(runner, dataloader)if isinstance (evaluator, dict ) or isinstance (evaluator, list ):self .evaluator = runner.build_evaluator(evaluator)if hasattr (self .dataloader.dataset, 'metainfo' ):self .evaluator.dataset_meta = self .dataloader.dataset.metainfoself .runner.visualizer.dataset_meta = self .dataloader.dataset.metainfoself .fp16 = fp16def run (self ) -> dict :self .runner.call_hook('before_val' )self .runner.call_hook('before_val_epoch' )self .runner.model.eval ()for idx, data_batch in enumerate (self .dataloader):self .run_iter(idx, data_batch)self .evaluator.evaluate(len (self .dataloader.dataset))self .runner.call_hook('after_val_epoch' , metrics=metrics)self .runner.call_hook('after_val' )return metrics @torch.no_grad() def run_iter (self, idx, data_batch: Sequence [dict ] ):self .runner.call_hook('before_val_iter' , batch_idx=idx, data_batch=data_batch)with autocast(enabled=self .fp16):self .runner.model.val_step(data_batch)self .evaluator.process(data_samples=outputs, data_batch=data_batch)self .runner.call_hook('after_val_iter' , batch_idx=idx, data_batch=data_batch, outputs=outputs)
跟到这里,差不多完整的 EpochBasedTrainLoop 与 ValLoop 流程就就很清晰了。
IterBasedTrainLoop 以及 TestLoop 与上述两者逻辑类似,不再赘述。
与 MMCV Runner 的对比
关于新版 MMEngine 中 Runner 与旧版 MMCV Runner 的差异,官方在 迁移 MMCV 执行器到 MMEngine 文档 中已经给出了比较详细的说明,这里仅选取几处个人感觉变化比较明显的点加以探讨。
优化器封装 OptimWrapper
在新版 MMEngine 中,官方对优化器做了一层封装:OptimWrapper ,按照文档描述,这层封装主要的目的在于:
MMEngine 实现了优化器封装,为用户提供了统一的优化器访问接口 。优化器封装支持不同的训练策略,包括混合精度训练、梯度累加和梯度截断。用户可以根据需求选择合适的训练策略。优化器封装还定义了一套标准的参数更新流程 ,用户可以基于这一套流程,实现同一套代码,不同训练策略的切换。
OptimWrapper 的源码实现位于 mmengine/optim/optimizer/optimizer_wrapper.py,从代码可以看出,除了封装 backward()、step()、zero_grad() 等基本操作外,OptimWrapper 还集成了如下功能:
get_lr(),get_momentum() 用于统一获取学习率/动量;state_dict() 与 load_state_dict() 方法批量导出/加载状态字典,这一点在管理多个优化器的时候会非常方便;optim_context() 、should_update()、_clip_grad() 等方法可实现混合精度训练、梯度累加/剪裁等高级功能;
在优化器的统一处理方面,由于涉及到的类型众多,笔者之前还没有看到过一套完整统一且便捷的解决方案,MMEngine 目前提供了一种很好的解决思路,尤其是在涉及多个优化器的应用场景,相比其他框架会有明显优势;
评估模块 Evaluator
在前面分析 ValLoop 时,简单提及了 evaluator 的构建与迭代流程:
验证循环中 run_iter() 调用的是 evaluator.process() 方法;
验证循环结束时调用的是 evaluator.evaluate() 方法来计算 metrics ;
这里再跟进源码看下评估模块的实现细节,相关文件位于 mmengine/evaluator/evaluator.py,其核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Evaluator :def __init__ (self, metrics: Union [dict , BaseMetric, Sequence ] ):self ._dataset_meta: Optional [dict ] = None if not isinstance (metrics, Sequence ):self .metrics: List [BaseMetric] = []for metric in metrics:if isinstance (metric, dict ):self .metrics.append(METRICS.build(metric))else :self .metrics.append(metric)def process (self, data_samples: Sequence [BaseDataElement], data_batch: Optional [Any ] = None ):for data_sample in data_samples:if isinstance (data_sample, BaseDataElement):else :for metric in self .metrics:def evaluate (self, size: int ) -> dict :for metric in self .metrics:return metrics
从上述片段可以看出,
evaluator.process() 实际会去调用 metric.process() 方法,其输入参数为 dataloader 返回的 data_batch 、包含了模型预测结果 predictions 与验证集 ground truth 数据的 _data_samples ;evaluator.evaluate() 会去调用 metric.evaluate() 方法;
再进入 mmengine/evaluator/metric.py 看一下 metric 的相关实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class BaseMetric (metaclass=ABCMeta): @abstractmethod def process (self, data_batch: Any , data_samples: Sequence [dict ] ) -> None : @abstractmethod def compute_metrics (self, results: list ) -> dict :def evaluate (self, size: int ) -> dict :self .results, size, self .collect_device)if is_main_process():self .compute_metrics(results)else :None ]self .results.clear()return metrics[0 ]
该类包含了2个抽象方法,为了便于理解,可以参考 mmdet/evaluation/metrics/coco_metric.py 中的子类 CocoMetric 进一步分析:
metric.process() 会处理一个 Batch 的数据以及对应的预测结果、标签等,并将其处理结果保存至 metric.results 中;metric.evaluate() 则会收集所有(分布式 rank 上的)处理结果,并调用 metric.compute_metrics() 计算最终指标;
至此,MMEngine 中的评估模块基本分析完毕,简单来说,虽然不同的 Metric 可能千差万别,但是可以将其封装成统一的类与接口,再使用 Evaluator 间接去调用这些接口,从而用统一方法实现不同的指标计算。
对比旧版 MMCV 基于 EvalHook 的实现方式,新版实现抽象程度更高,也相对更加灵活,这里采用的思想可以说与前述的 OptimWrapper 有异曲同工之妙。
数据预处理器 DataPreprocessor
细心的同学在使用新版 MMDetection 时,可能会发现,有些模型的配置中出现了 data_preprocessor 这个选项,根据官方 模型(Model) 描述,DataPreprocessor 至少可以完成如下功能:
执行数据搬运(如 CPU -> GPU)和归一化等功能;
执行数据批增强(BatchAugmentation),适用于 MixUp、Mosaic 这种需要融合多张图像的情况;
承担类型转换功能(DataLoader 的输出和模型的输入类型之间);
单看文字,或许还不是那么直观,这里还是跟进一下关键代码,基类 BaseDataPreprocessor 位于 mmengine/model/base_model/data_preprocessor.py :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class BaseDataPreprocessor (nn.Module):def __init__ (self, non_blocking: Optional [bool ] = False ):super ().__init__()self ._non_blocking = non_blockingself ._device = torch.device('cpu' )def cast_data (self, data: CastData ) -> CastData:if isinstance (data, Mapping):return {key: self .cast_data(data[key]) for key in data}elif isinstance (data, (str , bytes )) or data is None :return dataelif isinstance (data, tuple ) and hasattr (data, '_fields' ):return type (data)(*(self .cast_data(sample) for sample in data))elif isinstance (data, Sequence ):return type (data)(self .cast_data(sample) for sample in data)elif isinstance (data, (torch.Tensor, BaseDataElement)):return data.to(self .device, non_blocking=self ._non_blocking)else :raise TypeError('`BaseDataPreprocessor.cast_data`: batch data must contain ' 'tensors, numpy arrays, numbers, dicts or lists, but ' f'found {type (data)} ' )def forward (self, data: dict , training: bool = False ) -> Union [dict , list ]:return self .cast_data(data)
从上述代码可以看出基类的功能主要是执行数据搬运,跟进一个复杂些的子类,如 mmdet/models/data_preprocessors/data_preprocessor.py 中的 DetDataPreprocessor :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class DetDataPreprocessor (ImgDataPreprocessor ):def __init__ (self, mean: Sequence [Number] = None , std: Sequence [Number] = None , pad_size_divisor: int = 1 , pad_value: Union [float , int ] = 0 , pad_mask: bool = False , mask_pad_value: int = 0 , pad_seg: bool = False , seg_pad_value: int = 255 , bgr_to_rgb: bool = False , rgb_to_bgr: bool = False , boxtype2tensor: bool = True , batch_augments: Optional [List [dict ]] = None ):super ().__init__(if batch_augments is not None :self .batch_augments = nn.ModuleList(for aug in batch_augments])else :self .batch_augments = None def forward (self, data: dict , training: bool = False ) -> dict :self ._get_pad_shape(data)super ().forward(data=data, training=training)'inputs' ], data['data_samples' ]if data_samples is not None :tuple (inputs[0 ].size()[-2 :])for data_sample, pad_shape in zip (data_samples, batch_pad_shape):'batch_input_shape' : batch_input_shape,'pad_shape' : pad_shapeif self .boxtype2tensor:if self .pad_mask and training:self .pad_gt_masks(data_samples)if self .pad_seg and training:self .pad_gt_sem_seg(data_samples)if training and self .batch_augments is not None :for batch_aug in self .batch_augments:return {'inputs' : inputs, 'data_samples' : data_samples}
从上述代码可以看出,该类在父类 ImgDataPreprocessor 中执行了归一化、padding、rgb 转换之类的操作,在 forward 方法中会在 training 阶段执行定义的 batch_augments 相关批增强操作。
综上,简单来说,可以认为 DataPreprocessor 在 Model 与 Dataloader 之间建立了一种桥接关系,可以按需执行数据的 搬运、增强、转换 等操作。